

Calidad de Datos: BigDaPTOOLS
Software de Preprocesamiento en Big Data: Modelos y Herramientas para mejorar la calidad de los datos
Vivimos en un mundo en el que los datos se generan a partir de una multitud de fuentes, y es realmente barato recopilar y almacenar esos datos. Sin embargo, el beneficio real no está relacionado con los datos en sí, sino con los algoritmos que son capaces de procesar dichos datos en un tiempo tolerable, y de extraer de ellos valiosos conocimientos. Por lo tanto, el uso de las herramientas de Analítica Big Data proporciona ventajas muy significativas tanto para la industria como para el mundo académico.
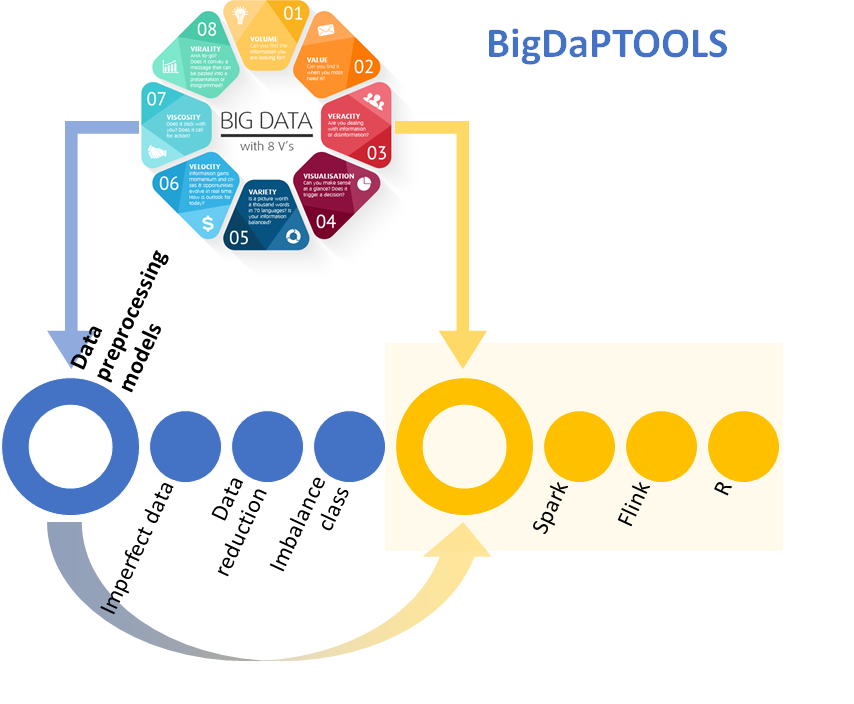
Las técnicas de preprocesamiento de datos se dedican a corregir o paliar errores en los datos. La reducción de dimensionalidad, de instancias, el filtrado de ruido y la discretización son ejemplos técnicas de preprocesamiento de datos más extendidas. Aunque podemos encontrar muchas propuestas teóricas para el preprocesamiento de datos y el Big Data, hay poco desarrollo software dedicado a la disposición libre de algoritmos en entornos Big Data.
BigDapTOOLS es un paquete de herramientas que nace con el objetivo de proporcionar y unificar los desarrollos software que estén relacionados con el preprocesamiento de datos y el Big Data. Este proyecto comenzó mediante la financiación de la Fundación BBVA. Hasta la fecha, disponemos de varios desarrollos realizados en tres plataformas bien conocidas en Ciencia de Datos, aunque el paquete seguirá creciendo en los próximos años. Los desarrollos destacados son:
- Software en R. Estos algoritmos abordan problemas como la reducción de datos con autoencoders, el preprocesamiento de datos para conjuntos de datos desequilibrados, datos ordinales y ruidosos, así como una librería de propósito general para el preprocesamiento de datos llamada ‘smartdata’, que recoge el estado del arte de los algoritmos para el preprocesamiento de datos en R, siendo un contenedor de algoritmos que proporciona una interfaz uniforme a otros paquetes. (https://sci2s.ugr.es/BigDaPR)
- Software en Spark. Apache Spark es un motor de código abierto desarrollado específicamente para manejar el procesamiento y análisis de datos a gran escala. El software desarrollado está disponible en Spark Packages y contiene un conjunto de algoritmos de preprocesamiento de datos para selección de características, discretización, filtrado de ruido e imputación de valores perdidos. (https://sci2s.ugr.es/BigDaPSpark)
- Software en Flink. Apache Flink es un marco de trabajo reciente y novedoso de Big Data, que sigue el paradigma de MapReduce, centrado en el procesamiento distribuido de datos en flujo y por lotes. Esta biblioteca contiene seis de los algoritmos de preprocesamiento de datos más populares para flujos de datos, tres para la discretización y el resto para la selección de características. El trabajo asociado está en: (https://arxiv.org/abs/1810.06021)
Periodo
Octubre 2016 – Presente
Investigadores
Francisco Charte, Alberto Fernández, Francisco Herrera, Salvador García, Julián Luengo, Sergio Ramírez, Diego Jesús García, Ignacio Cordón.